There have been a lot of news about increase in workplace management, as in remote monitoring, as many folks are either forced to or choose to work from home due to covid19.
It occurs to me that there might be some argument for the additions to the rights and freedoms of the individual. The company is a very powerful entity with a lot of resources at its disposal. In my past posts, I have argued for organizing labor for software engineers. It must be recognized that there is a gross disparity of power between individuals and their employers when it comes to the modern electronic work.
Okay, sure, yes, they teach in business school that information asymmetry is only way to get an edge. But considering the relationship as part of human society, we can clearly see that the individual has too little information and too little power to preserve their own human interests. If everyone had more power, there would not be a few billionaires and a lot of poorer people. Wealth and income inequality is really just a consequence of information and power inequality—secrecy and domination. So in some ways, by balancing the power of each individual versus the collective singular entity of a company, we may influence those inequalities that we care about.
So, for one example: it is publicly suggested by news media that most workplace computer have technologies that can: record what you type on it, live viewing or record video of screen as you use the computer, and remote alteration of computer files on your work computer. Although this sounds like science fiction to many, it may very well become true by the time you read this, the technology required to accomplish this not so far fetched. Let’s assume for this discussion that our world is one where such technology is in prevalent use.
These “solutions” that companies use were purchased for legitimate reasons. They need to keep people productive at work. They need to protect company secrets. They (hopefully) need to preserve workplace professional integrity. Sometimes they need to correct certain situations directly without passing through the chain of management. And many other reasons. The technology very directly solves these problem.
They may be right about what happened two hundred thousand years ago. The past is written but the Future is left for us to write, and we’d have powerful tools, Rios, Openness, optimism and the spirit of curiosity. All they have is secrecy and fear, and fear is the Great Destroyer, not…
Star Trek Picard S1
It seems in the fictional 24th century, they have been enlighten to the fact that secretive actions driven by fear is not the path, that there is a brighter way forward for everyone.
So, it is towards that end I consider the state of workplace monitoring. Perhaps we have not advanced, each of us as individuals and all of us as a civilization, to a level where we need no workplace monitoring—I mean if we had that we probably wouldn’t need laws and law enforcement either. But when we must have monitoring. When the humans in a company must play with god like powers, perhaps there should at least be transparency.
What I propose is very simple: employees who are under company surveillance and control must be given the information the company has collected on them. If the company makes a change to files on his computer, he must be informed of those changes. Equal power also means you have access to the tools they use to analyze your activities. If your boss had a dashboard where he can look into your bathroom visits, by day of week, by time of day, as measured by frequency and duration, you should have the same access to the same dashboard. If he knows how fast you type on Monday mornings before and after your coffee break, so should you, and with the same latency that he has. If he changes a file, maybe even a single letter, you should be informed of it.
Actually we can probably separate the employer activities into different levels of access:
- Lowest level:
- computer IO(screen recording and keyboard logger)
- audio-visual recordings
- Live monitoring of screen should be accompanied by a clearly visible signal to the employee that someone is watching live.
- Raw data files should be made available to the employee
- Aggregation and analysis
- Longitudinal data analysis
- Alerts generated by the employers systems
- Access to dashboards and analytics tools should be made available to the employee
- Decision making
- Explanation of why and AI made a determination for or suggestion to the company.
- I would ask for an explanation of why a human manager made a determination for or suggestion to the company,…, but that’s not the fairness I’m fighting for today.
- How a decision or determination was made must be communicated to the employee.
- Alterations and Interventions
- All changes the company makes to an employee’s files stored on company device or company cloud storage are relevant alterations.
- Alterations should be communicated to the employee immediately.
- The company should not assume that by moving the mouse on screen and typing the changes into the UI consist of informing the employee.
- Intentional retardation (or speeding up) of equipment performance: computation, inputs and commands to the computer, the computers user interface(UI) responses, network transmission, these interventions directed towards changing the employee or his direct activities are activities that must be firmly recorded and promptly communicated to the employee.
- The company should not represent that the alterations and interventions it made remotely to the computer data of an employee was made by said employee in any form or record such acts on media such that it is knowable to said employee, other employees, management or law enforcement.
- Additionally, it would be very irresponsible to understate the meta-requirement of employment. The amount of effort an employees or subjects should devote to monitoring of metrics the organization provides them as part of their jobs or subjugation, or as the case maybe, as part of their “relationship” or “complication”.
Also, to be perfectly clear, for all your quick-jerk reactionaries, I obviously mean employee should have access to recordings of their own activities and not other employees activities. Employees in management role with access to other employee’s data bear extra burden of integrity and responsibility.
I make these suggestion because I feel that they are essential to preservation of human workplace digital rights and digital integrity. In America, we can still dream of human freedoms and rights. In America we can speak opening about what we feel is right and just. We can still do right by ourselves and treat everyone with dignity and respect and trust and support.
And, I mean, think of it, you don’t want street riots in America when China or Russia or India or the EU announces human digital integrity and management transparency laws, do you? Following “I can’t breath,” may be “I can’t ty…” or shall we just follow GDPR X when it comes to pass ? The late-comer advantage is very clear here, it is much easier for technologically underdeveloped groups of people to establish new regimes in the technology that they build afresh than the established technology industry with “stuff that (still) works)” If you think you’re afraid of China having 5G, just wait till the worlds start copying the Russian constitution for rigorously defined and well balanced laws regarding digital rights and integrity. What truths do we hold evident then?
If we can just get these things right, then our world will flourish with the truly free use of our computers technologies to advance us. If we can treat each other with dignity and fairness, we can fly to the stars.
Let’s make it so!
P.s.
The need for disclosure to the monitored subjects does not rise to the level of medical and scientific disclosure to human experiment subjects. those pursuits tend to have higher-minded goals of universally improving human knowledge and life. Not all organizations have or need to be held to that standard.
Present demand for disclosure also does not invoke fundamental human rights, and leave that open to argument.
What we do stake support in is the need for governance of power. Corporations and other legal entities have power over individual human entities. Those powers must be kept in check. Just as companies are required to disclose the results of credit and background checks made for purpose of employment, advanced monitoring should also include mandatory disclosure of their products. Clearly we have great precedence for mandatory disclosure for other sensitive and private information regarding a person. And certainly, when something is done to a person’s he must be informed of those alterations. We should have it for all monitoring, recording and affectations targeting a person in presence of material power and information disparity.

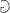 because it looks similar on my phone to the symbol I want. But here, I will use
because it looks similar on my phone to the symbol I want. But here, I will use 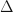 in place of
in place of  is a program that when applied to the program
is a program that when applied to the program 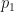 produces another program that can takes any input,
produces another program that can takes any input,  , of
, of  , a result that is equivalent to the second program run on the same input and environment
, a result that is equivalent to the second program run on the same input and environment  such that
such that  for some useful definition of
for some useful definition of  . This is the program difference(pd) between two programs.
. This is the program difference(pd) between two programs.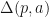 produces a function that can produce the change in
produces a function that can produce the change in  when a pd of its argument
when a pd of its argument  is offered
is offered  . That is:
. That is:  where the RHS partial evaluations are performed by partially specifying just the parameter
where the RHS partial evaluations are performed by partially specifying just the parameter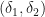 allows for reversible change if
allows for reversible change if  is an appropriately typed identity function. A single
is an appropriately typed identity function. A single  is an irreversible change. For one example, reading from a true random number generator would be an irreversible program. Inside the realm of a computer, simply reading an input from outside of the computer is an irreversible program within the computer, because it cannot affect the unpressing of the key. Even though outside of the computer we may know the reverse state of the “no” is the question“are you sure” from “rm -rf /“, the computer cannot know that for sure with its own faculties. That is to say, you cannot either, even if you are inside the computer and has access to just the computer memories and interfaces. Invertible pairs are intuitive, such as
is an irreversible change. For one example, reading from a true random number generator would be an irreversible program. Inside the realm of a computer, simply reading an input from outside of the computer is an irreversible program within the computer, because it cannot affect the unpressing of the key. Even though outside of the computer we may know the reverse state of the “no” is the question“are you sure” from “rm -rf /“, the computer cannot know that for sure with its own faculties. That is to say, you cannot either, even if you are inside the computer and has access to just the computer memories and interfaces. Invertible pairs are intuitive, such as  .
.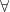 ? Elsewhere I have worked out the reparameterization to achieve
? Elsewhere I have worked out the reparameterization to achieve  . One of several example of this kind of reparameterization would be
. One of several example of this kind of reparameterization would be  each LHS and RHS now is requested to takes two parameters typed for
each LHS and RHS now is requested to takes two parameters typed for  , the first order equivalence, and so on. There are also sub-first-order equivalences such as: having at least same number of characters in the program code, that they are in the same language, etc. First order equivalence should minimally be a program having sufficiently compatible (-ly typed) input and outputs. Subsequently higher order equivalences include progressively more and more identical runtime behaviors or progressively more matching meaning. Here, again is another example of why presently described paradigm is beneficial: for example if a program is stochastic, how do we determine if another program is equivalent to it other than that the code is identical? By isolating the irreversible compute of receiving (from identical) external entropy, the remaining program can be evaluated in the
, the first order equivalence, and so on. There are also sub-first-order equivalences such as: having at least same number of characters in the program code, that they are in the same language, etc. First order equivalence should minimally be a program having sufficiently compatible (-ly typed) input and outputs. Subsequently higher order equivalences include progressively more and more identical runtime behaviors or progressively more matching meaning. Here, again is another example of why presently described paradigm is beneficial: for example if a program is stochastic, how do we determine if another program is equivalent to it other than that the code is identical? By isolating the irreversible compute of receiving (from identical) external entropy, the remaining program can be evaluated in the  order using conventional
order using conventional  . Further higher order equivalence may require that they have same runtime/memory/resource complexities. Which, btw, inspires an
. Further higher order equivalence may require that they have same runtime/memory/resource complexities. Which, btw, inspires an  ordering
ordering  that requires all equivalences
that requires all equivalences  and then at the
and then at the 
 was not necessary after all. As long as there is at least one “linear” layer at the output of the subnetwork that does not use the ExU or another sign-restricting foreactivation on the parameters, then the output can have a full range in R irrespective of input and therefore can be a universal regressor.
was not necessary after all. As long as there is at least one “linear” layer at the output of the subnetwork that does not use the ExU or another sign-restricting foreactivation on the parameters, then the output can have a full range in R irrespective of input and therefore can be a universal regressor. :
:

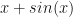

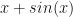
![\alpha \in (0, 1]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%280%2C+1%5D+&bg=ffffff&fg=111111&s=0&c=20201002) The hesitation layer
The hesitation layer  makes it possible to adjust the flat part of the sleep cycle. Here is
makes it possible to adjust the flat part of the sleep cycle. Here is 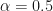 in blue next to the original:
in blue next to the original: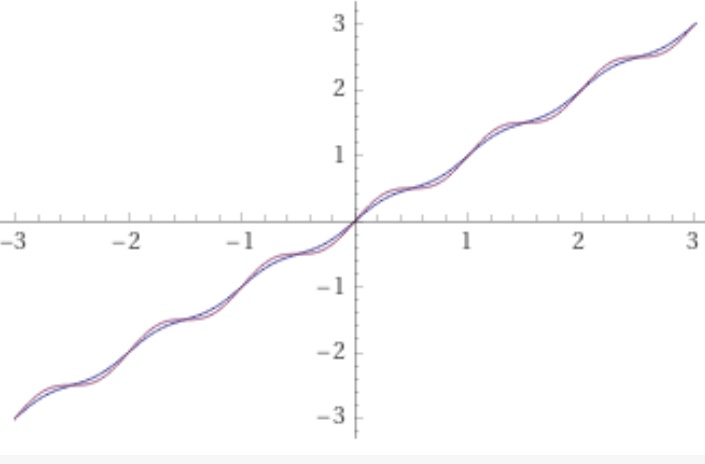

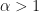 the hesitation layer becomes non-monotonic, but since Adam accumulates gradients, the gradient in the “wrong” direction will slow the progress of optimization more significantly than smaller
the hesitation layer becomes non-monotonic, but since Adam accumulates gradients, the gradient in the “wrong” direction will slow the progress of optimization more significantly than smaller  ’s. It will not necessarily produce an unrecoverable valley of local minimum. For
’s. It will not necessarily produce an unrecoverable valley of local minimum. For  this layer will not introduce new univariate local minimums or saddles to the optimization it is being added to. With randomization, the units will sleep at different times giving other paths of gradient that are not sleeping a chance to explore their potential to improve.
this layer will not introduce new univariate local minimums or saddles to the optimization it is being added to. With randomization, the units will sleep at different times giving other paths of gradient that are not sleeping a chance to explore their potential to improve.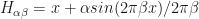 . Where
. Where  are either a single scalar or properly sized tensor for element-wise application. Generally the adjustment of
are either a single scalar or properly sized tensor for element-wise application. Generally the adjustment of  . Take the derivative wrt
. Take the derivative wrt  . So you see the gradient varies between
. So you see the gradient varies between ![[1-\alpha, 1+\alpha]](https://s0.wp.com/latex.php?latex=%5B1-%5Calpha%2C+1%2B%5Calpha%5D&bg=ffffff&fg=111111&s=0&c=20201002) times of
times of  ’s gradients.
’s gradients.