Some time ago we investigated the equality of benefits. Roughly speaking let us consider degenerate real world actions into discretely selectable choices of action 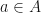 given individual
given individual  , who has observable features
, who has observable features  and protected feature
and protected feature  . Suppose the company has to choose among a set of actions to take
. Suppose the company has to choose among a set of actions to take 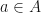 . What is a workable definite of fairness or equality in such a decision making effort with respect to protected properties
. What is a workable definite of fairness or equality in such a decision making effort with respect to protected properties  ?
?
Let god bestow us, a neutral third party, with a utility functor u whose evaluation on the individual 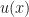 results in a function
results in a function  is the utility of company taking action a to individual ,
is the utility of company taking action a to individual ,  is the utility to individual of company taking action
is the utility to individual of company taking action 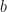 .
.
Let 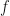 be the decision process of company
be the decision process of company  ,
,  is the decision company makes, some
is the decision company makes, some  for the individual . Then the right thing to do
for the individual . Then the right thing to do
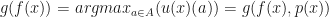
Simple, we do as god says, act as if we have the knowledge of an oracle–even when knowing some discriminable information that we then chose to ignore.
This is not as easy as it looks in a formula. Think of a person with a clown nose and one without, your behavior will likely be very different between those two persons, even if you decide that a clown nose has absolutely nothing to do with the task at hand.
Additionally, the nature of our imperfection dictates that our systems that we build are imperfect. What if we cannot achieve God’s will? What if we fail to do the virtuous even when we know what the right thing to do is?
What could a neutral thirdparty reasonably demand of a faulty company? One suggested approach is to establish probabilistic equality among protected classes. Suppose there are some number of classes,  which corresponds to values of p(x), between which we must protect their utility. (So for example M could be cartesian product of age, sex, race, birthplace, religion and political party)
which corresponds to values of p(x), between which we must protect their utility. (So for example M could be cartesian product of age, sex, race, birthplace, religion and political party)

That the customer utility for each class is identically some value  . This is a simplification as there are other classes of equivalence in stochastic variables.
. This is a simplification as there are other classes of equivalence in stochastic variables.
Note this framework has some slight benefit over traditional machine learning framework evaluating equality on confusion matrix of classifier performance g. There two most inspiring examples that I suffer from:
Situation 1: I noticed that my coworker was getting Tesla car advertisements while I do not receive one. Even though my utility in not receiving the advertisement was a negligibly loss–because I cannot afford a tesla, I still feel angry. I may even be tempted to find a protected attribute of mine to claim that tesla discriminated against me in its advertisement campaign: What! they think mid-aged Asian man can’t have a midlife crisis or can’t afford to splurge on a Tesla? In this case a true negative for prediction regarding response/conversion through a Tesla car Ad but offensive enough to cause problems. In retrospect this would have had positive utility for me, when I reached out to Tesla I learned more about how the car would work for me. But the decision seem to produce a negative sentiment from its subject.(The company has, since my drafting of this blog entry, sent me repeated invitation to test drive the S, perhaps due to recent but small increase in my disposable cash, which I may consider calling upon by taking the offer to test drive, at a suitable time. this is just an example)
Situation 2: I am offended when I do receive an advertisement for STD testing, and in particular for hepatitis family of diseases. For gods sake, there’s a Asian Liver Center at Stanford whose purpose for establishment is to check me for hepatitis or other Liver problems present in Asian livers. In this case, god bless me, that I am free of hepatitis and other liver problems of any kind, and that this is a false positive in advertising. I am offended. And in reality one may argue that the benefit of this advertisement, to me, to increase my chances of early detection is positive– I still feel offended. This case is a false positive to advertisement conversion. It is a positive utility to have shown it to me. And yet it produced negative sentiment.
I still feel offended. This case is a false positive to advertisement conversion. It is a positive utility to have shown it to me. And yet it produced negative sentiment.
Situation 3: I just received a piece of snail mail from a Redwood City mortuary advertising their service to Mr. And Mrs. Chang. I am terrified. I feel this is a death threat of some form. Putting the idea of me dying in Redwood City in my head. The letter has hand addressed envelope. This is a false positive for advertising relevance(I did not die, not yet any ways, and I am not planning on dying) it has zero utility for me, and I am definitely feeling very negative sentiment.
These are but several of many possible situations where the company could do the right thing in front of God, and in front of the board, by still be erring and thereby producing very negative sentiment. At risk of running out of numbers to enumerate all of them, I have not numbered all the types starting at 1.
To summarize, there are several factors that ultimately factor into a company’s decision making process, nonexclusively they are:
- The E.u.g.f for x, whether it is defensible in front of an oracle, God, or court of law;
- how will any action make the subject individual feel, the sentiment it produces, irrespective of objective utility;
- is utility function universally accepted;
- and finally the company’s bottom line.
With these considerations in mind, we can now continue with our exploration of fairness.


