I saw the tweet from Jack Dorsey live, yesterday–read it as the alerts came in. Twitter will disallow all political candidate and issues advertising. It chose to suffer this sacrifice to its income because it is felt that paid targeting gives political agents too much power to fool individual voters.
According to the news, Facebook has chosen to allow all political ads (for a few), in the name of freedom of speech. (And honestly, freedom of capitalism where the operations of capital is brought to bear in all organized activities)
I feel the righteousness of both sides. Hyper-targeting individuals, at their own stages of life, work, and living, at all times and places, it can overwhelm each of our senses so as to render our collective votes useless to the democracy. Scientifically, this theory stands. Rationally, the removal of organized political advertising means the discourse on twitter will be more democratic. It is a more real-time version of voting in some sense. This serves as a booster the value of each tweet as opinion of an entity and not effort of a political motivation. It corresponds to the source of what we value. It also boosts trustworthiness of the company possibly leading to more faithful users and promoters.
But refusing to sell a valuable commodity that you have an infinite supply of is very anti-free-market and anti-capitalism. What is this? A church state? The operation of business has to submit to the higher-than-thou self righteousness ?! That is so very un-American!! Who should decide what is a political issue and what is not? If climate watch group posts a new research, and advertises their finding, is that political or scientific? The detail of this scheme is devilish in that someone gets to make the call regarding whether a tweet is political or apolitical. This is a thinly vailed censorship with vast latitude for manipulation by twitter!
So, to organize these thoughts we can list the active constraints in this system
- Capitalism: Money should be able to buy or manipulate everything under human control. How money is used is the freedom bestowed by Capitalism on its constituents. In an ideally implemented market economy, money works just right automatically. Any restrictions to the power and flow of money detracts from Capitalism with free markets.
- Democracy: right of speech is necessary for the efficacious function of democracy. The purpose of speech as it pertains to democracy lie in the ability of speech to influence an audience, without audience and an affect, speech is irrelevant. (An extension of this speech-right-redux to right-to-be-heard might be the right to be found by internet search.) Reduction of the right to be heard detracts from Democracy. The increase of total paid political speech is effectively a decrease in everyone’s right-to-be-heard, and for all democratic intents and purposes paid political advertising is equivalent to buying away everyone else’s freedom to speech.
- Technology: we should try to grow and leverage our technology as much as we can. History has shown that invention and application of new technology repeatedly drove social progress in very significant ways. But history also shows that technologies destroy, consequently we have also chosen to set boundaries on our technology to ensure individual and social wellness: cars have speed limit and you “can’t buy a higher speed-limit”. Highly focused targeting and damaging machination like laser pointers are disallowed in most circumstances–and you can’t buy a permit for that either.
- Balancing Acts: the above constraints are balanced when interacting: One can only cast one vote, cannot buy votes no matter how much money or enthusiasm you have for a candidate or issue. Can’t lie in courts, can’t buy the right to lie in court. Cannot hack voting machines even if you have the technology and the money to do so.
I feel like the goalie at a world cups final overtime shootout–don’t know which company’s political advertisement policy to dive towards on this one.
But I will confirm that the fact that these two media giants feel enough freedom to take these divergent paths is great testament to American society. Our capitalism did not overwhelm every CEO to make the same decision when faced with trade off between those constraints. Our governments permits both paths to be taken. Our technology allows us to both implement and monitor the effects of these choices. The wide latitude they have to pursue that which is righteous is absolutely freaking awesome! That these transpired this week gives proof that America is greater!
 for identically distributed A in the two case where
for identically distributed A in the two case where  and
and 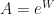 will vary but is largely dependent on A. If A is small, the SNR for
will vary but is largely dependent on A. If A is small, the SNR for  the larger the gradient step–mainly due to use of approximate second order SGD. My modification, as you would expect, allows the gradients to move more freely even if they are not normally distributed. The exponentiation of weights is akin to log-transform that we used in linear regression analysis, it lets us use linear methods that rely on normality of error on some systems with non-normally distributed, often heavy tailed, errors.
the larger the gradient step–mainly due to use of approximate second order SGD. My modification, as you would expect, allows the gradients to move more freely even if they are not normally distributed. The exponentiation of weights is akin to log-transform that we used in linear regression analysis, it lets us use linear methods that rely on normality of error on some systems with non-normally distributed, often heavy tailed, errors. is equivalent to the corresponding inverse power transform of power
is equivalent to the corresponding inverse power transform of power 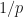 .
. used in Adam, it looks like an underflow because it fell below
used in Adam, it looks like an underflow because it fell below 