Several months ago I wrote about the Deep Universal Regressor. Hopefully you have discovered that it is full of bugs, fashioned typically for the late 2010’s, following Interweb AI blogging conventions of the day. It isn’t really because I’m time traveling and writing this from the far past or far future, just that this is the way we wrote in those days.
One most notable one is if you tried to regress  using my suggestion, you found that it does not extrapolate well. After some inspection, one realizes the problem. One way to fix it is to use a decision list to make progressively smaller estimates:
using my suggestion, you found that it does not extrapolate well. After some inspection, one realizes the problem. One way to fix it is to use a decision list to make progressively smaller estimates:

The  are linear activations from previous layers calculated from
are linear activations from previous layers calculated from 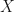 .
.
But of course, this approach also has some fatal flaws that needs to be fixed. Some effort has to be made to ensure the right term will be adjusted at the right moment–it needs regularization. It also needs some experimentation around what  is.
is.
After that, the  is the limit.
is the limit.
Ps, it’s kind of interesting that this range-preserving combination approach is slightly more general version of attention mechanism. Recall attention is applied as softmax combination of items of consideration. The softmax is just a positively weighted average, which in turn is a convex combination.
P.p.s. On the reverse side of this approach, perhaps we can apply activation in an earlier place to create similar effect. This approach is often taken to restrict parameter in a range, for example using 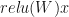 to produce a dense layer that applies only positive multiples to inputs. The approach I have tried with good success is the exponentiation activation.
to produce a dense layer that applies only positive multiples to inputs. The approach I have tried with good success is the exponentiation activation. 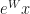 At first blush, you might judge this absurd. When we take a step, would the change in
At first blush, you might judge this absurd. When we take a step, would the change in  not be the same as the change in
not be the same as the change in  ? There is no contribution to complexity of the model in this parameter activation. If you look at it as
? There is no contribution to complexity of the model in this parameter activation. If you look at it as 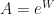 and then compute the output of the neuron as
and then compute the output of the neuron as  , the derivative of x with respect to A is linear in X. What difference does it make how you arrive at
, the derivative of x with respect to A is linear in X. What difference does it make how you arrive at  ?
?
But I have observed that the application of this activation makes linear regression converge faster under SGD. Looking at it more specifically 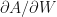 is
is  the parameter’s value is its own derivative. In other parlance the sensitivity of the derivative with respect to a parameter is linear in size of the neuron’s outputs. If A was just raw tensors, this derivative would be the constant
the parameter’s value is its own derivative. In other parlance the sensitivity of the derivative with respect to a parameter is linear in size of the neuron’s outputs. If A was just raw tensors, this derivative would be the constant  . Another consideration is that perhaps all we did was to initialize A using a log-normal or log-uniform distribution. Lastly, the effect of exponentiation maybe through the effect of increased or decreased learning rates. For this blogs purpose, I tried to implement a few of these alternative explanations directly with linear model: using log-normal initialization to a simple dense layer, trying various learning rates. These attempts did not produce the same quickened convergence as exponentiating the raw parameters.
. Another consideration is that perhaps all we did was to initialize A using a log-normal or log-uniform distribution. Lastly, the effect of exponentiation maybe through the effect of increased or decreased learning rates. For this blogs purpose, I tried to implement a few of these alternative explanations directly with linear model: using log-normal initialization to a simple dense layer, trying various learning rates. These attempts did not produce the same quickened convergence as exponentiating the raw parameters.
These meandering is of course a middle way between many. For example, if 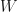 we’re not raw tensors but the output of some tensor function of the input, and we further normalize:
we’re not raw tensors but the output of some tensor function of the input, and we further normalize: this would be an attention mechanism like those used in transformers. Although the derivative of this is neither linear or constant.
this would be an attention mechanism like those used in transformers. Although the derivative of this is neither linear or constant.
Here is a list of parameter activations and their detivatives. Expressing in terms of A brings us a view of the scale of the gradient.
Clearly, its hard to boost the progress of training anymore this way.
Ppps ah, yes, astute you are, I have assumed positive data. The negative of can be concatenated as parameter or learned using a second layer or even a simple softened sign parameter. That should be exercise for reader to adapt to their own problems.
Pppps, This works so well, I want to name it, let’s call it autoactivation. In the tradition of autoencoders and similar to the auto- in autoimmune diseases, autoactivation means that the parameters of the network activate themselves, they are autoactivating. By the same convention, self-attention models are autoattentive.
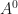




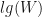
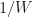
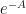

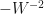
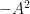



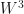

![3\sqrt[^3]{A^2}](https://s0.wp.com/latex.php?latex=3%5Csqrt%5B%5E3%5D%7BA%5E2%7D&bg=ffffff&fg=111111&s=0&c=20201002)
