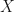There’s this idea in Deep Learning that Neural Networks are universal function approximates. They can approximate any function you can provide data for.
It has confounded me for a long time exactly how it does this for continuous valued output, but recently, through the grapevines that is the Deep Learning community, I finally discovered one answer to this question.
Consider some deep neural network taking in 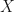

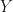

Oh boy, who are we kidding, let’s just drop down to tensorflow code…
You want to do

Being careful, of course, to calculate the pooling not for the batch but for each input and not to double sigmoid-activate 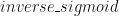

For example, if you think 
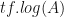
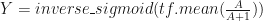
The 

![\frac{x}{\sqrt[1/k]{1+x^k}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bx%7D%7B%5Csqrt%5B1%2Fk%5D%7B1%2Bx%5Ek%7D%7D&bg=ffffff&fg=111111&s=0&c=20201002)

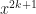

Tada!
This solves the problems of your deep neural network needing constricting nonlinearities like the sigmoids, your need to produce a continuous output that may grow at non-linear rates relative to activations, your limited computational resources, and your having a lucid hunch as to how they are related.
Hopefully this helps you and saves significant amount of brain activity and experimentation. Your problem will probably need a special architecture using a configuration of this pooling later.
P.s. the use of sigmoidal functions seems beckons to a probabilistic interpretation. The desigmoid, that’s inverse sigmoid, can be interpreted as a lookup from the CDF of a random variable, the value at which it achieves that accumulation. Essentially, in the most basic configuration, this regressor uses each element of A in the penultimate layer to support(or to reflect evidence that) that the desire

In one step, this regressor can consider both support for larger and for smaller value of Y.
P.p.s. Want to also put in a plug to our wonderful democracy. The computation of mean is explicitly mixing votes of each activation in the penultimate layer equally–each neuron gets an equal vote as to the result. Politics aside, and in addition to convex combinations, all other range preserving combination are fair game–e.g. geometric mean, softmax,etc. depending on the relationship between