Suppose I want my chatbot to be conservative in its learning, what are the ways we control that? There is dropout, and weight decay, and normalization. One idea was to find a way for it to learn and then sleep for a while before learning again. If we look at the gradient of such a function, it would look like 


This gradient is motivated by the want of rest period, when the input passes a certain periodic magnitude the progress of gradient based optimizer is gradually slowed down(but still pointed towards the same direction.) After the sleep, the function wants to progress fast to make up for the time spent sleeping, so the steps are bigger. A bit of manipulation of that expression produces the function with that gradient function
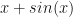

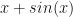
This addition of a hesitation can be used as a foreactivation (defined in previous FAM entries). Or in fact the hesitation layer can be placed any where a dropout is normally used.
A certain amount of experimentation is required to inject useful amount of randomization. This layer is particularly easy to instantiate after units that have known scaling, such as sigmoidal activations, softmax, batchnorm, and others. One formula in particular is amplitude. For ![\alpha \in (0, 1]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%280%2C+1%5D+&bg=ffffff&fg=111111&s=0&c=20201002)

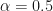
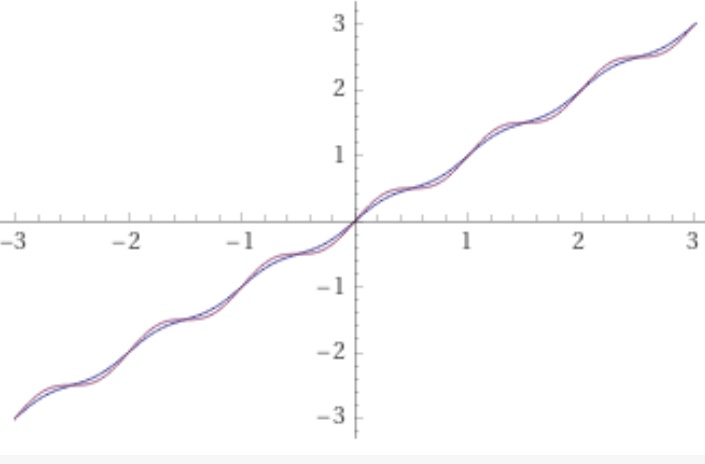

More work is needed to establish the precise effect this layer has different types of optimizers. For optimizers like Adam, the added variability would normally increase the noise of the gradients passing through the layer thereby effecting a reduction the learning rate. For 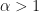


Another direction to explore is learnable sleep cycles in the form of 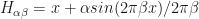

Wdyt?
Ps one can work out the gradient 


![[1-\alpha, 1+\alpha]](https://s0.wp.com/latex.php?latex=%5B1-%5Calpha%2C+1%2B%5Calpha%5D&bg=ffffff&fg=111111&s=0&c=20201002)

