Some months ago I wrote of a discovery regarding the training of deep regressors using SGD. I have since come to realize the benefit of exponentiating the raw parameters before using them is reasonable, sometimes. It would appear that for approximate second order optimizers, like Adam that I used instead of the SGD that I thought I used, the exponential has the effect of modulating the variance aspect of the optimization. The signal to noise ratio of gradients of 

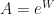
The combination of methods would tend to follow gradient more eagerly for neuronal activation less dependent on input than larger dependence on neuronal activation. This appear counter to my originally documented intuition that the larger the dependence neuronal output has on neuronal input 
Therefore although my success with this method stems more from the fortuitous conditioning of my problem than it does from the universality of the approach, it can make sense for a very large, albeit non-universal, set of problems. Subsequently any exponent 
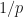
Stay tuned, more to come as I remove more bugs from the experiments.
