Suppose we have two groups of people experiencing different treatment–there is inequality of benefit between the two groups. We can write the difference between their benefits as:

Usually though, we can inspect the size of inequality using quadratic difference, or the quadratic inequality:

Take the expected value:
![E[(a-b)^2]](https://s0.wp.com/latex.php?latex=E%5B%28a-b%29%5E2%5D&bg=ffffff&fg=111111&s=0&c=20201002)
And rearrange to produce:

This formula can be read off easily. The quadratic inequality between group having 
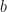

the mean difference in benefit, i.e. the mean-induced inequality between the two groups is a primal component of inequality,

which is the internal inconsistency of group
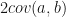
which says if treatment
To think through an example: suppose I benefit boys by giving or taking money from each by drawing a random number from 


There is an interesting side note from this branch of social science that in such a circumstance, the number of boys we must sample to ascertain a highly likely interval of his mean reward is lower than the number of girls we must see in order to ascertain the same likely interval of her mean reward. So, if the treatment of minority has high enough variability, then it becomes harder to be certain that there is mean-induced inequality. This decomposition enables us to identify such situations.
This is bit of Machine Learning math is really neat! We can now measure inequality in all aspects of life and understand, beyond an average, what is causing inequality and uncertainty.
